Einige Autoren dieses Blogs
Was machen wir, wenn die Pandemie tatsächlich nach Deutschland kommt? Wie können wir unsere Leserinnen und Leser am besten informieren? Können wir eine zentrale Anlaufstelle für Corona-Daten in Deutschland werden?
Es ist der 24. Februar 2020, Rosenmontag, als die Redaktion von ZEIT ONLINE in Berlin darüber diskutiert. “Nur für den Fall, dass in Deutschland bald erheblich mehr Covid-19-Fälle auftreten”, hatte Chefredakteur Jochen Wegner per Mail dazu eingeladen. An diesem Montag beraten wir, wie es gelingen kann, ZEIT ONLINE aus dem Homeoffice heraus aktuell zu halten. Haben alle Laptops? Hält der VPN-Zugang? Noch klingt all das für viele eher übervorsichtig, ja, ein wenig surreal. Die Pandemie scheint weit weg.
Zwei Tage danach, am 26. Februar 2020, zeigt ZEIT ONLINE als erste Redaktion eine Deutschlandkarte mit allen bekannten Sars-Cov-2-Infektionen in den Bundesländern – damals 23 Fälle. Eine zentrale Sammlung dieser Daten gibt es noch nicht. Informationen über bestätige Coronavirus-Fälle sammeln wir deshalb aus Meldungen der Deutschen Presse-Agentur und lokalen Medien. Und wir rufen mehrmals am Tag beim Robert Koch-Institut (RKI) an.
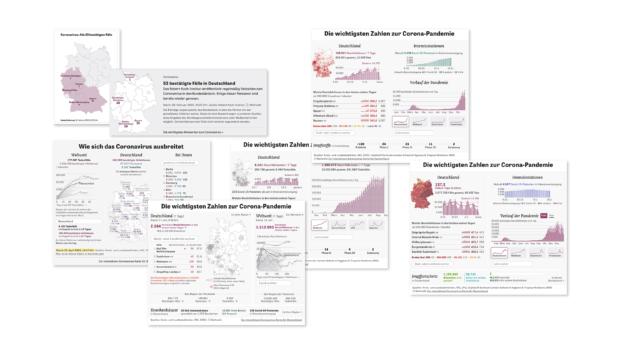
Heute, ein Jahr später, ist aus der Karte ein umfangreiches Dashboard mit allen wichtigen Kennzahlen der Pandemie geworden, von der Sieben-Tage-Inzidenz bis zur Impfquote. Millionen Menschen haben sich darüber informiert – und es ist bis heute eines der zentralen Elemente auf der Homepage von ZEIT ONLINE. Im Hintergrund sammelt unser Team fast rund um die Uhr Daten. Die Zahlen vom RKI und aus den Bundesländern liefert heute eine Software automatisiert. Daneben besuchen wir mehrmals täglich Hunderte Webseiten der Kreisämter. Warum wir das tun und was wir dabei gelernt haben, davon werden wir im Folgenden berichten.
Daten direkt aus 401 Stadt- und Landkreisen
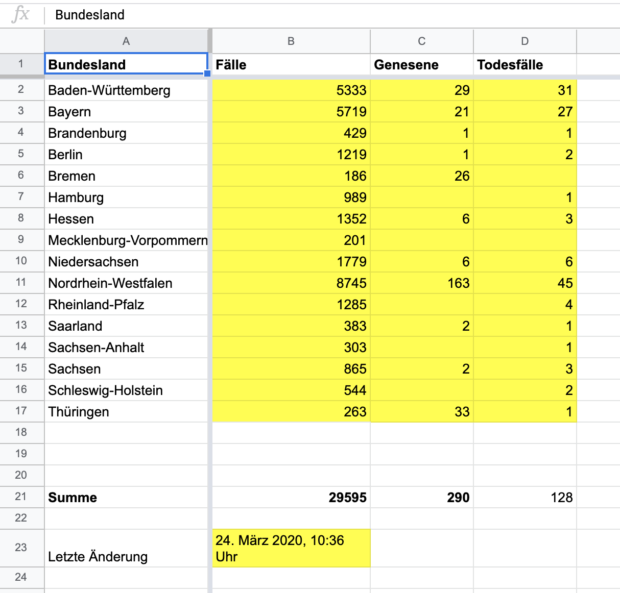
Mitte März 2020 stuft die Weltgesundheitsorganisation (WHO) den Ausbruch des Coronavirus offiziell als Pandemie ein. Auch in Deutschland gibt es immer mehr Fälle. In den ersten Wochen zeigt unser Dashboard, bei wie vielen Menschen der neue Erreger aus der Familie der Coronaviren in jedem Bundesland festgestellt wurde – und wie viele an den Folgen der Infektion, der Krankheit Covid-19, starben. Die Daten stellt das RKI inzwischen auf seiner Website täglich zur Verfügung. Doch auch die Ministerien der Bundesländer veröffentlichen mittlerweile eigene Zahlen – die sich teilweise erheblich von denen des RKI unterschieden. Der Grund: In der Meldekette von den Gesundheitsämtern über die Bundesländer an das RKI kommt es zu teils mehrtägigen Verzögerungen. Um möglichst aktuelle Zahlen zeigen zu können, besucht ein Team von Studentinnen und Studenten am Newsdesk von ZEIT ONLINE daher täglich die Websites der Bundesländer. Die Daten tragen sie in ein einfaches Google-Sheet ein.
Doch nicht nur ZEIT ONLINE sammelt Daten zur Pandemie. Der freie Journalist René Engmann verfolgt schon seit Januar 2020 alle Entwicklungen rund um das Coronavirus. Er kann nicht verstehen, dass es in den ersten Tagen der akuten Krisensituation keine offizielle und tagesaktuelle Quelle für die Daten gibt – und fängt einfach selbst an zu sammeln. Über Twitter werden wir auf ihn und seine damalige Plattform coronavirus.jetzt aufmerksam. Vor allem weil er schon früh eine Liste mit den Infektionszahlen aus allen Stadt- und Landkreisen zusammenstellt. Auch unsere Redaktion will das Infektionsgeschehen noch regionaler als auf Ebene der Bundesländer abbilden und entscheidet deshalb, mit ihm zu kooperieren und die Zahlen von nun an direkt aus den Gesundheitsämtern zu beziehen.
Der erhebliche Aufwand zahlt sich aus. Nicht erst als die Bundesregierung im Mai lokale Grenzwerte beschließt, an denen sich Lockerungen und Verschärfungen der Maßnahmen in einzelnen Regionen orientieren – und wir aktuellere Zahlen als das RKI zeigen können. Zwischenzeitlich werden unsere Daten sogar von der renommierten Johns-Hopkins-Universität zitiert, die als eine der zuverlässigsten Quellen für internationale Daten zum Coronavirus gilt. Lange wird sich unser Team an den Moment erinnern, als die Zahlen, die wir aus dem Homeoffice teilweise am Küchentisch oder mit Kindern auf dem Schoß eingepflegt haben, kurz darauf auf der Seite der New York Times zu sehen sind.
Ständig neue Kennzahlen
Als im Frühjahr die Fallzahlen rasant ansteigen, wird schnell klar, dass nicht nur die absoluten Fallzahlen wichtig sind. Gerade die Entwicklung ist entscheidend – und gleichzeitig schwer zu verstehen. Exponentielles Wachstum, Verdopplungszeiten, die Reproduktionszahl R: Wie können wir das alles möglichst einfach für unsere Leserinnen und Leser aufbereiten? Als die Corona-Fälle so schnell zunehmen, dass auf unserer Grafik im internationalen Vergleich kaum noch etwas zu erkennen ist, entscheiden wir uns, den Verlauf auf einer logarithmischen Achse zu zeigen. Durch die gestauchte Achse werden zwar höhere Werte besser vergleichbar, doch gleichzeitig hören wir auch Kritik: Die neue Darstellung erschwere es, die Zahlen richtig zu interpretieren. Heute bietet ZEIT ONLINE beide Darstellungen an. Dies ist nur ein Beispiel für die vielen Designentscheidungen, die wir oftmals in wenigen Stunden treffen mussten.
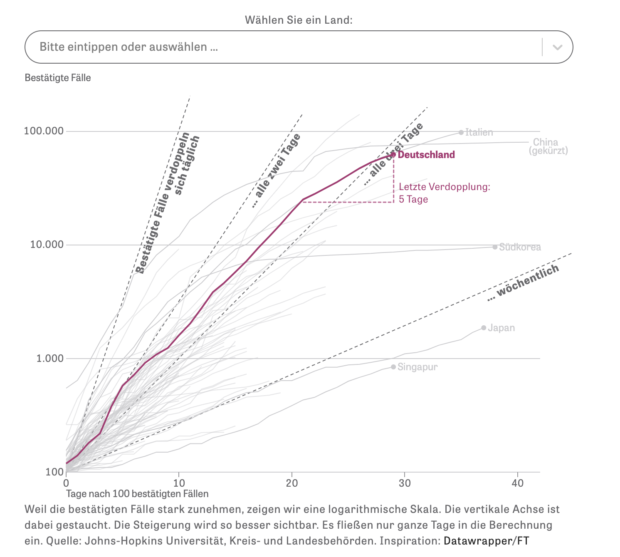
Längst sind die bestätigten Infektionen und Todesfälle nicht mehr die einzigen Kennzahlen, die das Dashboard zeigt. Seit Mitte April beziehen wir tagesaktuelle Daten zur Belegung der Intensivstationen mit Covid-19-Patientinnen und -Patienten aus dem Divi-Intensivregister des RKI. Das Robert Koch-Institut meldet mittlerweile auch wöchentlich Zahlen von Tests und Testpositivraten, einem Indikator für eine mögliche Überlastung der Gesundheitsämter.
Auch 2021 kommen neue Kennzahlen der Corona-Pandemie hinzu, wie etwa Daten zu verabreichten Impfdosen in den Bundesländern – und seit Neuestem auch zur Verbreitung der Coronavirus-Mutationen. Um die Zahlen aus Deutschland auch international vergleichen zu können, setzen wir außerdem auf Daten der Johns-Hopkins-Universität, der WHO und der Plattform Our World in Data.
Doch wie verlässlich sind diese Zahlen – und welche sind überhaupt wichtig? Wie finden wir eine Balance, um einerseits den Ernst der Lage zu kommunizieren, dabei aber andererseits nicht alarmistisch zu sein? Und wie gehen wir damit um, dass es bei vielen der Daten große Unsicherheiten gibt? Immer wieder diskutiert die Redaktion darüber, immer wieder überarbeiten wir unsere Texte und Visualisierungen. Und immer versuchen wir, unsere Änderungen und Überlegungen in Methodikboxen und Infokästen möglichst transparent darzustellen.
Eine große Unterstützung in diesem Prozess sind unsere Leserinnen und Leser. Noch nie haben wir für ein Projekt so viel und so regelmäßiges Feedback bekommen wie für die Corona-Daten. Im Laufe des Jahres sind unter dem Artikel zum Dashboard mehr als 22.000 Kommentare zusammengekommen. Darunter viel Lob, aber auch Kritik. Wenn ein Fehler passiert oder die Zahlen besonders stark von denen der lokalen Behörden abweichen, fällt das meist sofort jemandem auf. Selbst über neue Features diskutieren wir mittlerweile im Kommentarbereich unter dem Artikel, bevor wir sie veröffentlichen.
Unsere Arbeitsweise hat sich im letzten Jahr grundlegend verändert: Vor der Pandemie arbeitete unser Team aus Journalistinnen, Entwicklerinnen und Designern meistens an größeren Projekten, bei denen wir viel Zeit für die Analyse und Visualisierung hatten. Nach der Veröffentlichung waren unsere Projekte im Normalfall abgeschlossen – nicht so im Fall des Corona-Dashboards. Und auch das, was wir uns in der Redaktionskonferenz im Februar noch kaum vorstellen konnten, ist mittlerweile Alltag: Das Team, das das Dashboard betreut, arbeitet seit fast einem Jahr komplett aus dem Homeoffice – in Schichten von 7 bis 22 Uhr, unter der Woche und am Wochenende.
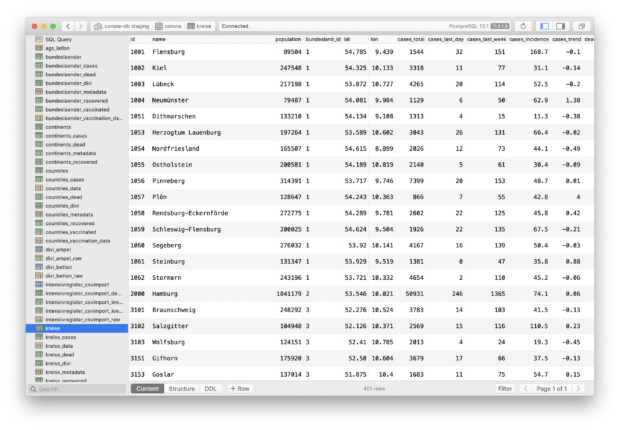
Falls es Sie interessiert, geben wir im Folgenden einen Einblick in die Software und Tools, mit denen wir jeden Tag arbeiten: Die mittlerweile beinahe unüberschaubare Menge an Daten von bestätigten Fällen bis weltweiten Impfquoten speichern wir in einer sogenannten Postgres-Datenbank, die über eine GraphQL-Schnittstelle sehr kurze Ladezeiten und ein flexibleres Arbeiten für etwa Datenanalysen ermöglicht. Neben der manuellen Eingabe, lesen sogenannte Webscraper Zahlen von verschiedenen Webseiten automatisch ein und werden in der Datenbank zusammengeführt. Diese Scraper programmieren wir in Javascript und Python und führen sie durch sogenannte Cronjobs im Minutentakt aus. Geodaten wie die Deutschlandkarte bearbeiten wir mit der Open-Source-Software QGIS. Daten analysieren wir mit der Statistiksoftware R oder Jupyter Notebook. Die Designs entwickeln wir gemeinsam mit der Software Figma, häufig bauen wir die ersten Version unserer Grafiken mit dem Tool Datawrapper. Die interaktiven Grafiken auf der Website bestehen aus der Javascript-Bibliothek D3 und React-Komponenten. Um den Überblick zu behalten organisieren wir uns mit dem Browsertool Trello und kommunizieren über Slack und Zoom.
Diese Personen haben alle im Laufe des Jahres mitgearbeitet: Joe Bauer, Paul Blickle, Fabian Dinklage, René Engmann, Elena Erdmann, Alexander Eydlin, Linda Fischer, Flavio Gortana, Carla Grefe-Huge, Katharina Heflik, Sophia Hofer, Alena Kammer, Moritz Klack, Matthias Kreienbrink, Andreas Loos, Christopher Möller, Valentin Peter, David Schach, Stephan Scheying, Anna Lena Schlitt, Max Skowronek, Ivana Sokola, Julian Stahnke, Johann Stephanowitz, Jona Spreter, Sven Stockrahm, Julius Tröger, Sascha Venohr, Konstantin Zimmermann
Mega gut – danke für die Einblicke und die Informationsaufbereitung!
Vielen Dank für die außerordentlich zuverlässige und strukturierte Aufarbeitung der Daten.
Der Überblick und die Informationen, die Sie jedem Laien verständlich präsentieren, ist etwas, dass ich gegenwärtig aus meinem Alltag nicht wegdenken kann. Regelmäßig schaue ich das Geschehen über Ihre Karte an und baue Hoffnung auf, wenn die Farben heller werden..
Der schnelle Zugriff auf verlässiche Informationen ist mitunter das wichtigste Tool, um daraus rasche Konsequenzen abzuleiten und diese Pandemie (hoffentlich) in den Griff zu bekommen.
Also noch einmal vielen Dank für diesen wertvollen Beitrag und Ihre Arbeit.
Vielen Dank an alle Beteiligten für die Mühe und die vielen tollen Ideen, die in dieses Projekt eingeflossen sind.
Meines Wissens ist es die einzige Seite, auf der die Zahlen für die EU als Ganze verfügbar sind.
Die Zeitrafferkarte, auf der man den Beginn der zweiten Welle schon im August erkennen kann, halte ich jedem unter die Nase, der von überzogenen Maßnahmen spricht.
Abschließend hätte ich eine Bitte: Könnten für das Vereinigte Königreich auch die Todeszahlen des ONS benutzt werden(https://www.ons.gov.uk/peoplepopulationandcommunity/birthsdeathsandmarriages/deaths/datasets/weeklyprovisionalfiguresondeathsregisteredinenglandandwales)? Die entsprechen am ehesten denen des RKI.
vielen dank und große anerkennung für das daten-team! die karten und daten sind für mich eine wichtige tägliche orientierungshilfe.
Vielen Dank für die harte Arbeit! Ich schaue täglich drauf. Vor allem die Impfkarte ist im Moment sehr interessant.
Sobald es die Daten hergeben, wäre die lokale Verteilung der Varianten interessant. Und die absoluten Zahlen als zwei Grafen in einem Bild. Dann wäre leichter verständlich, warum die Zahlen inzwischen trotz Einschränkungen wieder steigen, bzw. ob die Varianten dahinter stecken.
Ich möchte mich an dieser Stelle mal ausdrücklich für eure Arbeit bedanken, das macht ihr richtig gut. Das Tool hat mir das ganze letzte Jahr täglich sehr geholfen mit der Situation besser klarzukommen. Ich hoffe ihr bekommt dafür mindestens einen Preis in der Wertigkeit des Bundesverdienstkreuzes, oder mit was ihr euch sonst wertgeschätzt fühlt.
Interessant!
Geil, auch wenn das Thema ernst ist. Freue ich mich über Hintergründe der Entstehung und Technik zu lesen.
Danke für die Erklärung.
Frage zu
Die mittlerweile beinahe unüberschaubare Menge an Daten von bestätigten Fällen bis weltweiten Impfquoten speichern wir in einer sogenannten Postgres-Datenbank
Wie groß ist die DB mittlerweile und wie sind die Specs der HW?
Wird timescaledb auch genutzt?