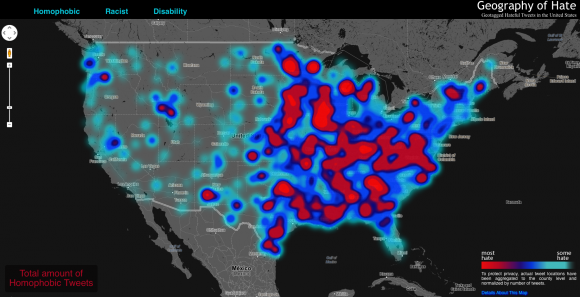
Die Welt des Internets ist zweigeteilt. Es gibt die Sphäre der Nutzer und die Sphäre der Domaininhaber, also jener, die das Netz mit Inhalten füllen. Das Verhältnis der beiden ist ungleich verteilt, wie Karten zeigen, die das Oxford Internet Institute (OII) veröffentlicht hat.
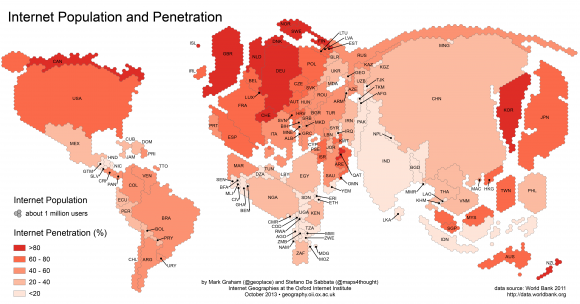
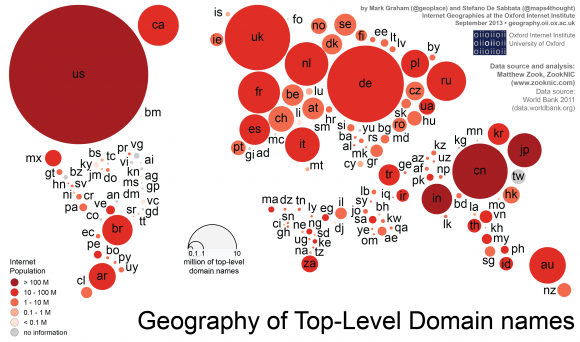
Die Mehrheit der Domains im Netz ist in Nordamerika und in Europa registriert – fast ein Drittel aller Websites weltweit gehört Menschen und Organisationen in den USA, schreiben Mark Graham und Stefano De Sabbata vom OII.
Die Mehrheit der Internetnutzer hingegen lebt in China, das Land stellt die größte Internetpopulation der Welt. Gleichzeitig sind dort nur wenige Domains zu Hause.
Die Wissenschaftler nutzen als Vergleich den Wert User pro Domain, der sich ergibt, wenn man die Zahl der Nutzer eines Landes mit der Zahl der Domains dort ins Verhältnis setzt.
Weltweit errechneten sie den Durchschnitt von zehn Nutzern pro Domain. In den USA liegt dieser Wert bei drei. In China hingegen sind es pro Domain 40 Nutzer. Dort seien weniger Websites registriert als beispielsweise in Großbritannien.
Dieses Missverhältnis zeigt sich überall: Die Inhalte werden von Amerikanern und Europäern dominiert, der Rest der Welt schaut zu. Italien und Vietnam zum Beispiel haben nahezu die gleiche Zahl an „Netzbewohnern“, aber in Italien sind sieben Mal so viele Websites registriert wie in Vietnam.
Das beobachteten sie sogar in Japan. Dort leben zwei Mal so viele Netznutzer wie in Großbritannien, es sind dort aber nur ein Drittel so viele Websites registriert wie im Königreich.
Insgesamt sind 78 Prozent aller Domainnamen in Nordamerika oder Europa beheimatet. Asien kommt noch auf 13 Prozent der Domains, in Lateinamerika, Ozeanien und Afrika sind es jeweils weniger als fünf Prozent. Und so gibt es in Afrika mehr als 50 Nutzer pro Domain – viele Konsumenten, kaum Produzenten also.
Insgesamt leben inzwischen 42 Prozent aller Netznutzer in Asien. Und dort ist auch noch viel Wachstum möglich, da gleichzeitig die Durchdringung in Ländern wie Indien und China gering ist, also nur vergleichsweise wenige Bewohner des Landes auch im Netz sind.
Es gebe, schreiben Graham und De Sabbata, eine starke Korrelation zwischen dem Pro-Kopf-Bruttoeinkommen eines Landes (Gross National Income per capita) und der Zahl der Domains. Das Netz hat die Möglichkeit, Inhalte zu verbreiten, stark vereinfacht. Geld kostet das aber noch immer. Und so ergibt sich im Verhältnis von Produzenten und Konsumenten eine fast koloniale Struktur.
Zur Berechnung verwendeten die Wissenschaftler Zahlen aus dem Jahr 2013, die von Matthew Zook von der University of Kentucky zur Verfügung gestellt wurden.
Um das Ergebnis nicht zu verfälschen, wurden Domains von Ländern wie Tuvalu, Armenien oder Tokelau nicht berücksichtigt. Sie gehören zu denen, die weltweit gern registriert werden, weil ihre Domainendung so beliebt ist, oder weil die Registrierung nichts kostet. Domains mit .tv, .am oder .fm werden beispielsweise gern von Medienunternehmen aus aller Welt gebucht, .re von Réunion ist beliebt bei Immobilienmaklern, da es die englische Abkürzung für real estate ist.