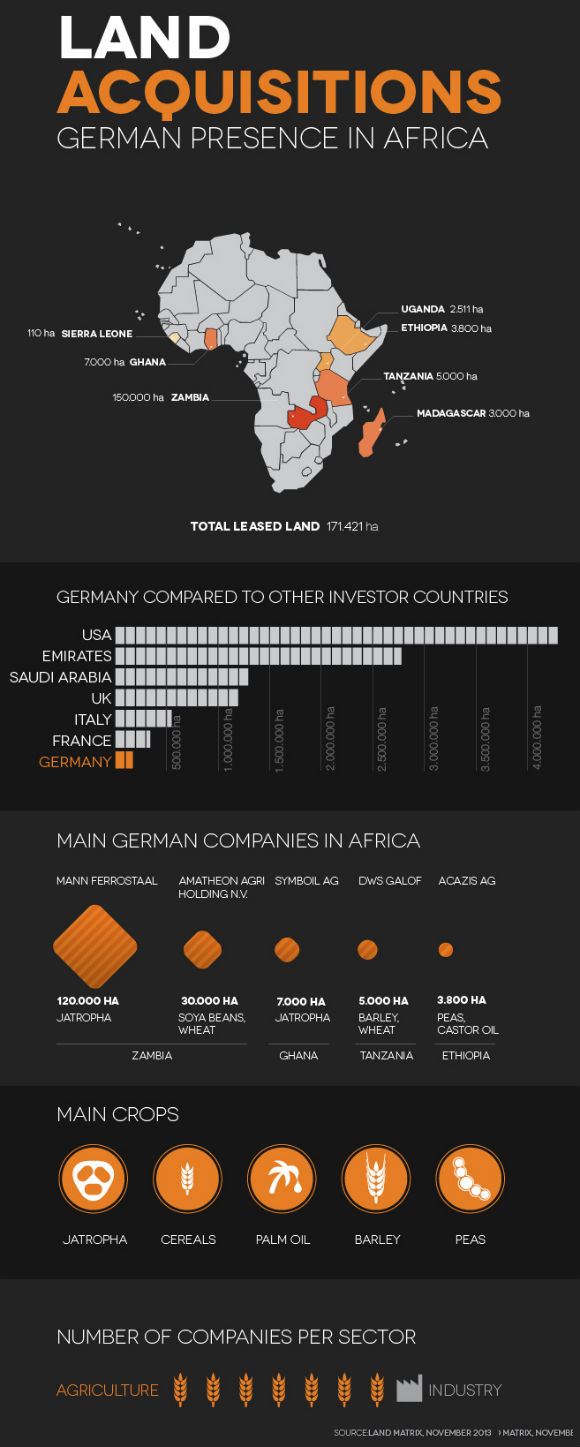
Deutsche Investoren sind an acht von 356 transnationalen Verträgen beteiligt, die für die Verpachtung von Land in Afrika geschlossen wurden und insgesamt eine Fläche von etwa 171.000 Hektar umfassen. Dies geht aus einer Recherche in der Datenbank Land Matrix hervor. Diese Datenbank erfasst großflächigen Landerwerb und wurde von vier internationalen Forschungsinstituten, unter anderem dem GIGA (German Institute of Global and Area Studies) und der GIZ (Deutsche Gesellschaft für Internationale Zusammenarbeit) entwickelt. Ein eher geringer Anteil, verglichen mit den führenden Investorenländern – allein die USA, die Vereinigten Arabischen Emirate, das Vereinigte Königreich und Saudi-Arabien kontrollieren zusammen 9.6 Millionen Hektar Land auf dem Afrikanischen Kontinent. Trotzdem war Deutschland bereits Gegenstand harscher Kritik bezüglich Kaweri, einer Kaffee Plantage in Uganda, die Teil der Neumann Kaffee Gruppe Hamburg war. Die im speziellen an den Bundesminister für wirtschaftliche Zusammenarbeit und Entwicklung, Dirk Niebel, gerichteten Vorwürfe, ähneln denen, die sich an andere des „Land Grabbing“ Verdächtigte richten. Der Begriff „Land Grabbing“ bezeichnet die Aneignung riesiger Landflächen in Entwicklungsländern bei gleichzeitiger Verletzung der Menschenrechte lokaler Gemeinschaften.
Deutschlands wichtigste Landgeschäfte in Afrika
Aus den zum jetzigen Zeitpunkt von Land Matrix erfassten Verträgen geht hervor, dass die acht von deutschen Investoren in Afrika abgeschlossenen Verträge sich auf eine Fläche von insgesamt 171.000 Hektar belaufen. Fünf Projekte haben offensichtlich bereits mit der Produktion begonnen, wohingegen drei sich offenbar erst in der Anfangsphase befinden. Die 2500 Hektar, die von Uganda an die Kaffee Gruppe verpachtet wurden -1802 davon werden genutzt- gehören offenbar zu denjenigen Projekten die bereits angelaufen sind. Vier der acht Investitionen dienen offenbar dem Anbau von Jatropha, einer Pflanze aus der Öl für die Produktion von Biodiesel gewonnen wird. An das Biotreibstoffgeschäft gekoppelt ist auch die größte Investition von 120,000 Hektar in Sambia, die sowohl an die Deutsche Firma Mann Ferrostalla als auch an Deulco, eine südafrikanische, auf erneuerbare Energien spezialisierte Firma verpachtet wurden. Letztere ist das einzige Projekt, welches auch als „Industrie“ aufgeführt ist und sich damit höchstwahrscheinlich auf die Jatropha-Öl Umwandlungsanlagen bezieht. Die anderen vier Investitionen setzen sich aus Plantagen zum Zweck der Nahrungsmittelgewinnung zusammen: Reis, Getreide, Erbsen, Korn und Kaffee.
Groß angelegter Landerwerb in Afrika
Wie viele Hektar sind seit dem Beginn des „Landrauschs“ insgesamt verpachtet worden? Jeder Versuch sich dem Umfang dieses Phänomens zu nähern, sieht sich unweigerlich mit einer Vielzahl widersprüchlicher Zahlenangaben konfrontiert. Die Weltbank führt 56 Millionen verpachtete Hektar allein für die Zeit zwischen 2008 und 2009 infolge der Preisexplosion bei den Nahrungsmitteln an. Das International Food Policy Institute und das Oakland Institute kommen auf 15-20 Millionen Hektar im Zeitraum von 2006 bis 2009. 2011 berechnete die erwähnte „Land Matrix“ die Größe des verpachteten Landes seit dem Jahr 2000 auf die riesige Fläche von 227 Millionen Hektar (Zum Vergleich: Deutschland umfasst 35,7 Millionen Hektar). Errechnet von nicht immer vertrauenswürdigen Quellen, wurde diese Einschätzung, nach einem Relaunch der Datenbank im Juni 2013, auf 33 Millionen Hektar, die durch unterschriebene Verträge nachgewiesen werden konnten, verringert. Dies entspricht einer Fläche etwa acht mal so groß wie die Niederlande.
„Es ist schwer zu sagen, ob diese Zahlen mit hinreichender Wahrscheinlichkeit korrekt sind“, sagt Andrea Fiorenza, Forscher der International Land Coalition und Co-Autor einer Reihe von Studien, genannt Commercial Pressure on Land, denn „manche Projekte fangen an, sehen sich dann diversen Problemen gegenüber und laufen aus und werden abgebrochen, oder ganz im Gegenteil, dehnen sich über die legalen Grenzen hinweg aus.“ Darüber hinaus verhindert mangelnde Transparenz der Regierungen in Entwicklungsländern ein klareres Bild der Situation. Das Ziel der „Land Matrix“ Datenbank ist jedoch nicht, die endgütige Datenlage zu präsentieren, sondern „Trends zu erkennen, aus verschiedenen Quellen zu schöpfen und auf dem Laufenden zu bleiben.“
Erkunden sie die globale Debatte über den „Landrausch“
Für detaillierte Informationen über den groß angelegten Landerwerb wurde eine interaktive Karte erstellt, auf der Artikel zur Debatte über den Landrausch in Afrika gesammelt werden. Hier sind Dokumente der akademischen Welt, Berichte der internationalen Zivilgesellschaft, journalistische Recherchen und Stellungnahmen von Unternehmen und Institutionen zum Thema verlinkt. Außerdem ist es möglich, der Karte neue Artikel hinzuzufügen, indem dieses Formular ausgefüllt wird.
Erkunden sie die Karte durch Klicken auf die Markierungen und beteiligen sie sich an der Diskussion, indem sie die Karte, unter Angabe von Link, Ort und Quelle, mit weiteren Dokumenten verlinken, die sie für relevant in der Auseinandersetzung um Landverpachtungen auf dem Afrikanischen Kontinent halten.
Über das Projekt
Jacopo Ottaviani ist Journalist und Entwickler, spezialisiert auf Datenjournalismus. Er arbeitet für italienische und internationale Medien, unter anderem The Guardian und Al Jazeera International.Folgen Sie ihm auf Twitter: @jackottaviani
Dieser Beitrag für ZEIT ONLINE ist Teil des Innovation in Development Reporting Programms des European Journalism Centre (EJC). Zur Projektentwicklung haben außerdem Andrea Fama, Cecilia Anesi und Isacco Chiaf beigetragen. Hier geht es zur englischen Version des Beitrags.