 Im Deutschen Bundestag ist es ruhig geworden: Die Sitzungstage sind vorbei, nur noch ein paar Ausschüsse werkeln vor sich hin. Die meisten Abgeordneten sind in der Sommerpause oder bereits im Wahlkampf. In gut sechs Wochen, am 22. September, wird der nächste Bundestag gewählt.
Im Deutschen Bundestag ist es ruhig geworden: Die Sitzungstage sind vorbei, nur noch ein paar Ausschüsse werkeln vor sich hin. Die meisten Abgeordneten sind in der Sommerpause oder bereits im Wahlkampf. In gut sechs Wochen, am 22. September, wird der nächste Bundestag gewählt.
Was bleibt von dieser 17. Legislaturperiode? Wie hart haben die Fraktionen gearbeitet? Wie aktiv oder untätig waren die einzelnen Abgeordneten? Hat sich das Engagement der Oppositionspolitiker von denen der Spitzenpolitiker unterschieden, was machen die unterschiedlichen Spitzenpolitiker, und was eigentlich die Hinterbänkler?
Diese Fragen haben uns – Sascha Venohr als Head of Data Journalism, die Entwicklungsredakteure Martina Schories und Paul Blickle und die Politikredakteurin Lisa Caspari – beschäftigt. Auf der Grundlage Zehntausender Daten wollen wir eine Art finden, mit der sich die komplizierte und komplexe parlamentarische Arbeit von Parlamentariern verständlich und anschaulich darstellen lässt.
Die Aktivitäten der Abgeordneten sind öffentlich: Sie werden auf der Website des Deutschen Bundestags bis ins Detail protokolliert. Die Datenquelle heißt Dokumentations- und Informationssystem – kurz DIP. Jeder, der will, kann hier jede Information zu den 620 Abgeordneten erhalten. Theoretisch jedenfalls. In der Praxis ist es nicht nur schwierig, sich auf der Seite zurechtzufinden, sondern auch einen Überblick oder gar Vergleichsmöglichkeiten zu bekommen.
Um die Daten grafisch aufzuarbeiten, haben Martina Schories und Sascha Venohr die Dokumentation des DIP gescrapt. Scrapen bedeutet, dass ein kleines Programm so tut, als wäre es ein Benutzer, der verschiedene Suchanfragen an eine Website stellt und dabei die gewünschten Ergebnisse gesammelt abspeichert. Es wurden alle im DIP dokumentierten Aktivitäten von Abgeordneten zwischen dem 27. September 2009 und dem 28. Juni 2013 abgefragt, von der ersten bis zur letzten offiziellen Sitzungswoche. Wertvolle Ratschläge, das DIP zu verstehen, bekamen wir dabei vom Team von OffenesParlament, das schon länger Daten aus dem Dokumentationssystem des Bundestages auswertet und veröffentlicht.
Die Datenmasse, die ZEIT ONLINE durch die zahlreichen Anfragen an das DIP heruntergeladen hat, war riesig; das Laden der Daten dauerte manchmal mehr als eine Nacht. Insgesamt wurden 155.965 Aktivitäten ausgelesen, jede ist einem Parlamentarier zuweisbar. Zunächst arbeiteten wir mit CSV-Dateien, die zum Schluss für jede Aktivität eine Zeile enthielten. Danach wurden die Daten bereinigt, was an einigen Stellen anspruchsvoll war: Einige Abgeordnete hatten in dieser Legislaturperiode geheiratet und waren deswegen unter zwei verschiedenen Namen zu finden; herausgefiltert werden mussten außerdem Bundesratsmitglieder, die im Plenum tätig geworden waren.
Auch nach dem letzten Sitzungstag trug die Bundesverwaltung noch Daten zur Legislaturperiode nach. Erst am 19. Juli 2013 war die Dokumentation vollständig. Die Größe des Datensatzes sprengt jedes Google-Doc, daher können wir nur eine abgespeckte Version veröffentlichen. Sie ist hier einzusehen. Generell gilt: Die Daten spiegeln ausschließlich die Arbeit der Abgeordneten im Plenum des Bundestages wider. Die Arbeit in den Ausschüssen verzeichnet das DIP hingegen leider nicht.
Politikredakteurin Lisa Caspari hat schließlich die Daten aufgearbeitet und inhaltlich gewichtet. Zum besseren Verständnis bildete sie fünf Oberkategorien für die insgesamt 24 vom DIP erfassten Sorten von Aktivitäten. Die Kategorien heißen Rede, Wortbeitrag, Gruppeninitiative, Frage an die Bundesregierung und Antwort der Bundesregierung.
- Rede
- Eine im Plenum vorgetragene oder aus Zeitgründen zu Protokoll gegebene Rede eines Abgeordneten wurde als Rede kategorisiert.
- Wortbeiträge
-
Ein Beitrag eines Abgeordneten im Plenum, der keine ausformulierte Rede ist, wird als Wortbeitrag definiert. Dazu gehört ein Antrag zur Geschäftsordnung, eine Zwischenfrage bei einer Rede, eine Zusatzfrage in einer Fragestunde an die Bundesregierung, eine Kurzintervention im Parlament, eine Erwiderung auf die Antwort eines Abgeordneten sowie die Persönliche Erklärung gemäß §32GOBT, die Mündliche Erklärung zur Abstimmung (§31GOBT) und die Schriftliche Erklärung zur Abstimmung (§31 GOBT), in denen Abgeordnete ihre abweichende Meinung zum Thema kundtun. Sowie die mündliche Erklärung gemäß §91 GOBT, die (Mündliche) Erklärung zur Aussprache gemäß §30 GOBT und die Erklärung zum Plenarprotokoll.
- Gruppeninitiativen
- Ein Gesetzentwurf mehrerer Abgeordneter oder einer Fraktion sowie ein Antrag, Entschließungs- oder Änderungsantrag werden als Gruppeninitiative definiert. Damit eine dieser Vorlagen angenommen wird, muss sie mindestens von fünf Prozent aller Abgeordneten unterschrieben sein. Für seine Fraktion berichtet zumeist ein Abgeordneter im Bundestag aus dem Ausschuss. Auch das wurde als Gruppeninitiative kategorisiert, weil der Abgeordnete stellvertretend für seine Fraktionskollegen spricht.
- Frage
- Die Opposition kann schriftliche Fragen an die Bundesregierung stellen, die diese zu beantworten hat. Es wird unterschieden zwischen kleinen Anfragen zu Sachthemen und großen Anfragen zu zentralen politischen Debatten. Zudem kann jeder Abgeordnete pro Sitzungswoche bis zu zwei Fragen an die Bundesregierung einreichen, die in den Fragestunden jeden Mittwoch an den Sitzungstagen beantwortet werden.
- Antwort
- In der Fragestunde gibt ein Mitglied der Bundesregierung, meist die Parlamentarischen Staatssekretäre, einen mündlichen Bericht zum Thema der Kabinettssitzung ab und beantwortet die Fragen der Abgeordneten. Diese Tätigkeit ist in den Plenarprotokollen als „Berichterstattung und Beantwortung“ und “Antwort” dokumentiert. Im Oktober 2009 kamen noch 28 Antworten von ehemaligen SPD-Staatssekretären und Ministern der großen Koalition.
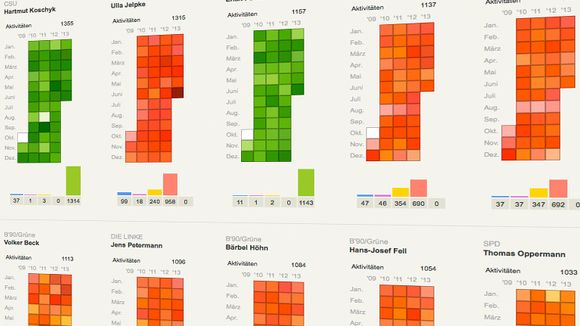
Mithilfe der Oberkategorien erstellte Infografiker Paul Blickle ein visuelles Konzept zur Aufarbeitung des Datenwusts. Jeder Tätigkeitskategorie wurde eine Farbe zugeordnet und für jeden Abgeordneten eine farbliche Übersicht angefertigt. Sichtbar ist nun ein Kalender mit gefärbten Kästchen für jeden Monat der 17. Legislaturperiode.
So lässt sich auf einen Blick erkennen, in welcher der fünf Kategorien der Abgeordnete seine Arbeitsschwerpunkte setzte. Je intensiver der individuelle Farbwert erscheint, desto aktiver war der Abgeordnete in diesem Monat; Beiträge in verschiedenen Kategorien führen zu Mischfarben. Die fünf Kategorien, die wir für die Einordnung der Arbeit im Bundestag verwenden, finden sich auch als Sortierkriterium wieder. Beispiel: Durch einen Klick auf die Kategorie “Reden” werden die Politiker mit den meisten Reden am Anfang der Liste angezeigt. Durch den Klick auf eine Partei kann der aktivste Redner aus deren Fraktion herausgefiltert werden.
Die zentralen inhaltlichen Ergebnisse unserer Daten-Aufarbeitung hat Lisa Caspari in ihrem Artikel “Die große Abgeordneten-Bilanz” zusammengefasst. Verwiesen sei auch auf den Artikel “Sichtbare und unsichtbare Promis”, der sich mit den Aktivitätsunterschieden zwischen Peer Steinbrück und Angela Merkel befasst. In den kommenden Tagen folgen Interviews mit Spitzenreitern in den verschiedenen Kategorien.
Trotz all der schönen Spitzenwerte und Ranglisten – absolute Aussagen über das politische Engagement der Politiker kann unsere Aktivitätsbilanz nur bedingt treffen. Viele Politiker, die im Parlament im Vergleich zu anderen nicht allzu aktiv waren, hatten dafür gute Gründe: Manche haben ein hohes Parteiamt inne, andere konnten gesundheitsbedingt weniger leisten, als sie wollten. Eine schwächere Farbe oder ein längerer weißer Zeitraum im Kalender eines bestimmten Abgeordneten bedeutet also nicht automatisch, dass er faul war.
Technisch bietet unsere Grafik die Möglichkeit, einzelne Politiker “auszuschneiden”, um sie in andere Websites einzufügen. Den Embed-Code können Sie der Grafik entnehmen. Die Adresszeile im Browser ändert sich, wenn mit der Grafik interagiert wird, wenn also Filter eingestellt werden. Zum Beispiel gelangen Sie mit diesem Link zur Liste aller Angehörigen der Linkspartei im Bundestag. Die Liste zeigt zudem ein Ranking nach der Anzahl der Fragen an die Bundesregierung – gefiltert lediglich für Linke-Abgeordnete. Wolfgang Nešković — der einzige Politiker im Bundestag, der keiner Fraktion angehört — ist nur über diesen Link zu erreichen. Die Navigation beinhaltet keinen Weg zu ihm.
In der Infografik ist zudem jede der 155.965 Aktivitäten eines Abgeordneten verlinkt – auf die jeweiligen Protokolle in der Bundestagsdokumentation. Schauen Sie sich einmal um!