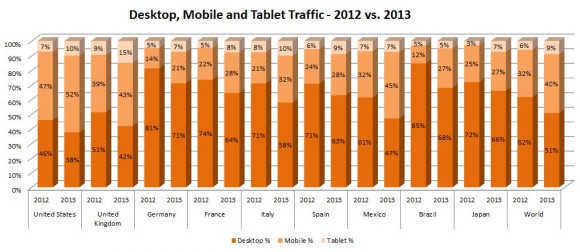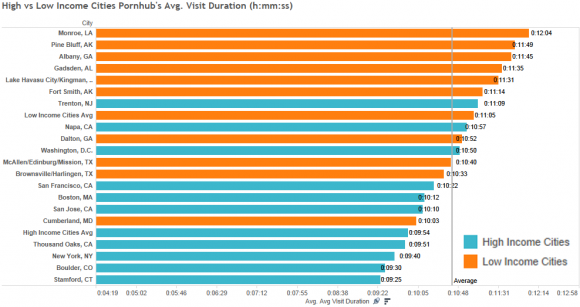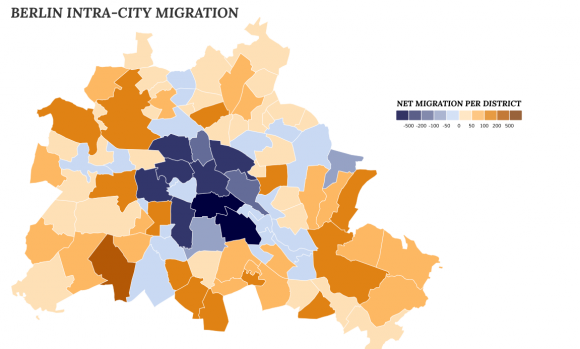
Daten verbrauchen sich nicht. Mit neuen Fragen lassen sich auch aus alten Daten immer wieder neue Erkenntnisse gewinnen. Patrick Stotz und Achim Tack liefern dafür mit ihrem Projekt Mappable ein Beispiel.
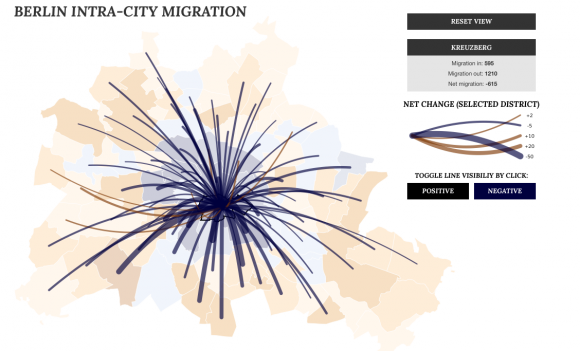
Sie haben alte Telefonbücher aus den Jahren 2004 bis 2012 gekauft und die Daten aus Berlin genutzt, um darin nach Menschen zu suchen, deren Adresse sich im Laufe der Zeit geändert hat. 50.000 haben sie eindeutig identifizieren können, schreiben sie in ihrem Blog zu dem Projekt. Die Umzüge dieser 50.000 innerhalb der Stadt haben sie anschließend auf einer Karte visualisiert. Die Karte zeigt nun, wohin die Menschen in Berlin ziehen.
Das erzählt einiges darüber, wie die Stadt funktioniert.
Demnach ziehen aus den Bezirken Kreuzberg und Neukölln die meisten Menschen weg. Beide sind auf der Karte tiefblau, was für eine hohe Netto-Abwanderung spricht. Gleichzeitig schrumpft die Bevölkerung dort jedoch nicht und aus Berlin selbst ziehen wenige Menschen dorthin. Was bedeutet, dass beide so etwas wie ein Hafen für Einwanderer sind. Offensichtlich ziehen viele, die nach Berlin kommen, erst einmal dorthin. Kreuzberg und Neukölln gelten als spannend, bunt und zentral, die Mieten sind insgesamt trotzdem vergleichsweise niedrig. Entweder verdrängt der Zuzug viele der Alteingesessenen, oder die Neubewohner überlegen es sich später anders und wandern in andere Bezirke weiter.
Den größten Netto-Zuzug in Berlin hat Zehlendorf, ein reicher und ruhiger Bezirk im Südwesten. Die meisten Zuzügler kommen aus Wilmersdorf, Charlottenburg und eben aus Kreuzberg. Das würde die These des Einwanderer-Hafens stützen.
Das ist ein für viele Großstädte klassisches Muster: Junge Menschen ziehen in die Innenstadt, wenn sie für Beruf oder Studium kommen. Wenn sie älter werden, suchen sie ruhigere und auch teurere Bezirke am Rand. Mappable belegt diese Theorie. Und die Telefonbuchdaten erlauben es sogar, das genauer zu tun als die offizielle Statistik. Die kennt als kleinste Ebene nur den Stadtbezirk. Mappable bricht die Daten auch auf Ortsteile herunter und kann damit ein granulares Bild zeichnen.
Es ist nicht das erste Mal, dass Telefonbücher als Datenquelle genutzt werden, um soziologische Aussagen zu treffen. Aber die Umzugsanalyse ist ein interessanter Ansatz. Die beiden Entwickler sind optimistisch, dass sie mit ihrer Idee eine neue Datenquelle erschlossen haben. In ihrem Blog schreiben sie:
„To sum things up: we are quite enthusiastic about the potential of phone directories as a data source and there are definitely more research questions that can be answered with these data sets besides only migration patterns (e.g. monitoring gentrification processes, identifying ethnicity patterns).“